A Comprehensive Overview to Applying Scalable Databases Without the Demand for Coding Experience
In the contemporary landscape of information monitoring, the ability to apply scalable databases without coding knowledge is ending up being significantly essential for organizations of all dimensions. This overview intends to brighten the procedure, concentrating on user-friendly tools and intuitive interfaces that demystify data source configuration. By analyzing essential features, effective strategies for implementation, and ideal techniques for recurring monitoring, we will certainly attend to exactly how even non-technical users can confidently browse this facility surface. What are the important elements that can absolutely encourage these customers to utilize scalable data sources effectively? The responses might redefine your technique to data monitoring.
Recognizing Scalable Databases
In the realm of contemporary data monitoring, scalable databases have actually become an important solution for companies seeking to take care of boosting volumes of info efficiently. These data sources are designed to fit development by allowing for the smooth addition of resources, whether via horizontal scaling (including much more equipments) or vertical scaling (updating existing machines) This versatility is important in today's busy digital landscape, where information is generated at an extraordinary price.
Scalable data sources usually utilize dispersed architectures, which allow information to be spread throughout numerous nodes. This distribution not only boosts performance however additionally offers redundancy, making certain information schedule even in the occasion of hardware failings. Scalability can be a vital factor for numerous applications, including shopping platforms, social media networks, and huge information analytics, where customer need can fluctuate substantially.
Furthermore, scalable databases usually feature durable information uniformity versions that stabilize efficiency and reliability. Organizations must consider their particular demands, such as read and compose speeds, data stability, and fault tolerance when choosing a scalable database option. Eventually, recognizing the underlying concepts of scalable databases is vital for services aiming to thrive in a progressively data-driven world.
Trick Features to Seek
When reviewing scalable databases, a number of key features are extremely important to ensuring ideal performance and integrity. First and leading, consider the architecture of the database. A distributed architecture can boost scalability by permitting data to be stored throughout numerous nodes, assisting in seamless information gain access to and processing as demand rises.
An additional important function is data dividing, which allows efficient monitoring of big datasets by dividing them right into smaller sized, much more manageable items (no-code). This technique not only improves efficiency however likewise simplifies source appropriation
In addition, search for robust duplication capabilities. This feature makes certain data redundancy and high availability, reducing downtime during upkeep or unexpected failings.
Performance monitoring devices are also essential, as they supply real-time insights into system health and wellness and operational effectiveness, enabling timely changes to preserve optimal efficiency.
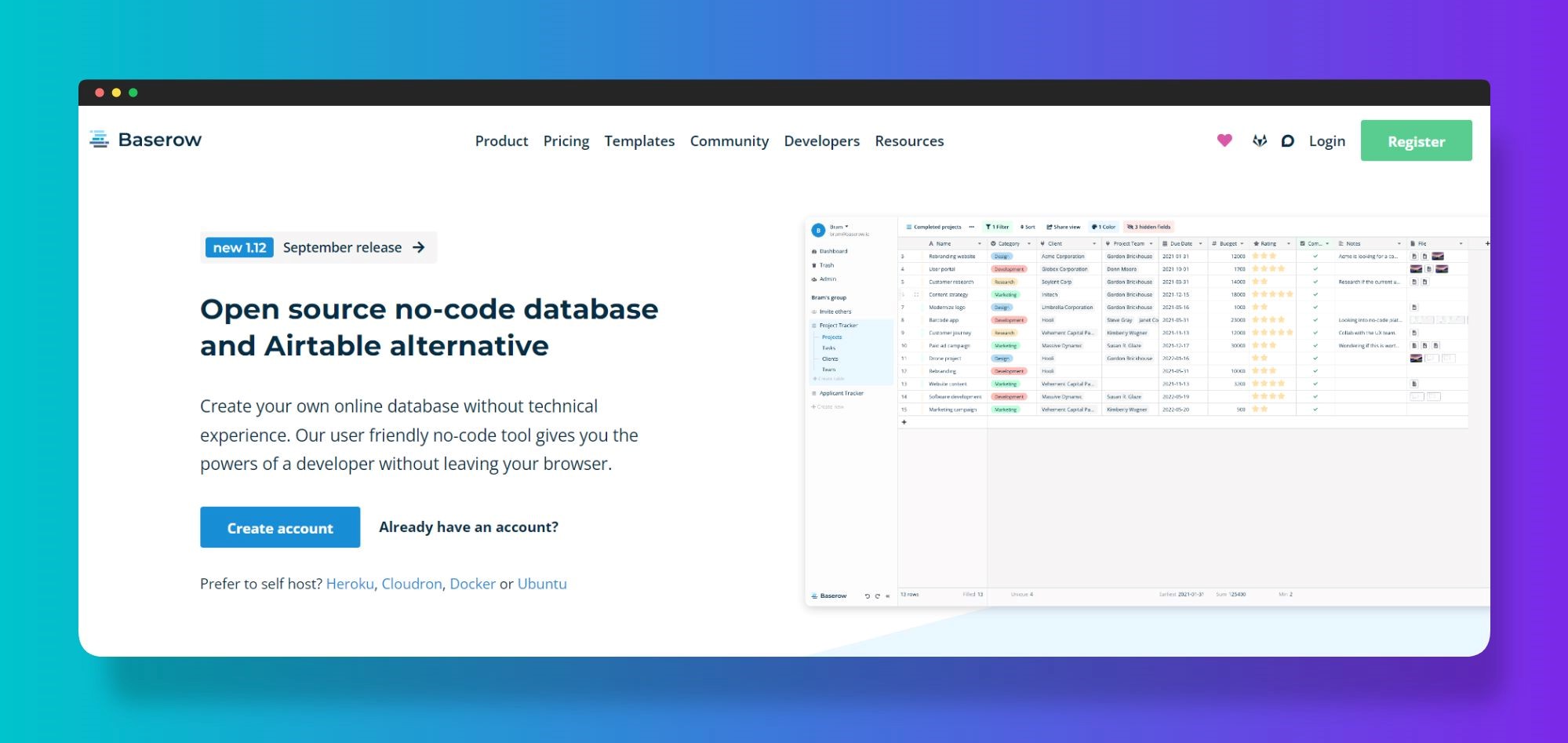
User-Friendly Data Source Equipment
Simplicity is a crucial component in the style of easy to use data source tools, as it boosts access for users with varying levels of technological experience. no-code. These devices focus on intuitive user interfaces, allowing users to develop, handle, and question databases without requiring substantial programming expertise
Secret features commonly include drag-and-drop capability, visual information modeling, and pre-built design templates that streamline the configuration process. Such tools often supply directed tutorials or onboarding procedures that assist in user involvement and decrease the understanding curve. In addition, seamless combination with popular data resources and services makes sure that customers can easily import and export information, further simplifying procedures.

Additionally, robust assistance and neighborhood sources, such as online forums and documentation, enhance the customer experience by giving help when needed. On the whole, straightforward data source tools encourage organizations to harness the power of scalable databases, making information administration accessible to every read the article person included.
Step-by-Step Implementation Overview
Exactly how my response can organizations effectively carry out scalable databases to fulfill their growing information requirements? The process starts with determining details data needs, including the quantity, variety, and rate of data that will certainly be processed. Next, companies ought to review easy to use data source tools that supply scalability functions, such as cloud-based remedies or handled data source services.
Once the appropriate tool is selected, the following step entails configuring the database setting. This includes establishing instances, defining individual approvals, and establishing data frameworks that line up with organization purposes. Organizations must then move existing data right into the new system, ensuring data honesty and marginal disruption to procedures.
Post-migration, conducting comprehensive testing is essential; this includes efficiency testing under various tons conditions to make certain the system can deal with future development - no-code. Furthermore, it is necessary to train staff on the data source administration user interface to promote smooth use
Ideal Practices for Monitoring
Reliable administration of scalable databases needs a strategic strategy that prioritizes ongoing tracking and optimization. To attain this, companies need to execute durable monitoring tools that provide real-time insights into database efficiency metrics, such as question response times, resource utilization, and purchase throughput. Consistently evaluating these metrics can aid recognize bottlenecks and areas for enhancement.

Regular back-ups and calamity recuperation strategies are necessary to guard data stability and schedule. Establishing a routine for examining these backups will certainly make certain a trusted recovery process in situation of an unforeseen failure.
Furthermore, efficiency adjusting must be a constant process. Adjusting indexing strategies, optimizing questions, and scaling resourcesâEUR" whether up and down or horizontallyâEUR" will help maintain optimum efficiency as usage demands advance.
Last but not least, fostering a society of expertise sharing among team members will enable constant knowing and adaptation, guaranteeing that the management of scalable data sources remains efficient and effective in time.
Conclusion
Finally, the implementation of scalable data sources can be properly accomplished without coding knowledge via the usage of instinctive user interfaces and easy to use tools. By adhering to the described approaches for configuration, data migration, and efficiency testing, people can browse the complexities of data source monitoring effortlessly. Stressing finest practices for recurring maintenance and partnership additional enhances the ability to manage scalable databases efficiently in a quickly advancing data-driven atmosphere.
In the modern landscape of data administration, the capability to apply scalable data sources without coding experience is becoming increasingly vital for organizations of all sizes.In the world of modern information management, scalable data sources have emerged as a crucial remedy for companies looking for to take care of boosting quantities of details efficiently.Furthermore, scalable data sources often feature durable data uniformity models that stabilize efficiency and reliability.Exactly how can companies properly implement scalable databases to fulfill their growing information requirements? Next, organizations ought to assess user-friendly data source tools that offer scalability attributes, such as cloud-based options or managed data source services.
Comments on “Why No-Code is the Future of Open System Data Source Development for Services”